The EngageAI Institute team has devised a multimodal video analysis framework for measuring student engagement and analyzing collaborative problem-solving activities. The framework enables automated analysis of videos showing student interactions with narrative-centered learning environments in K-12 classrooms to drive automated analysis of learner engagement. This information can help researchers and teachers better understand how to support engaged learning in classrooms.
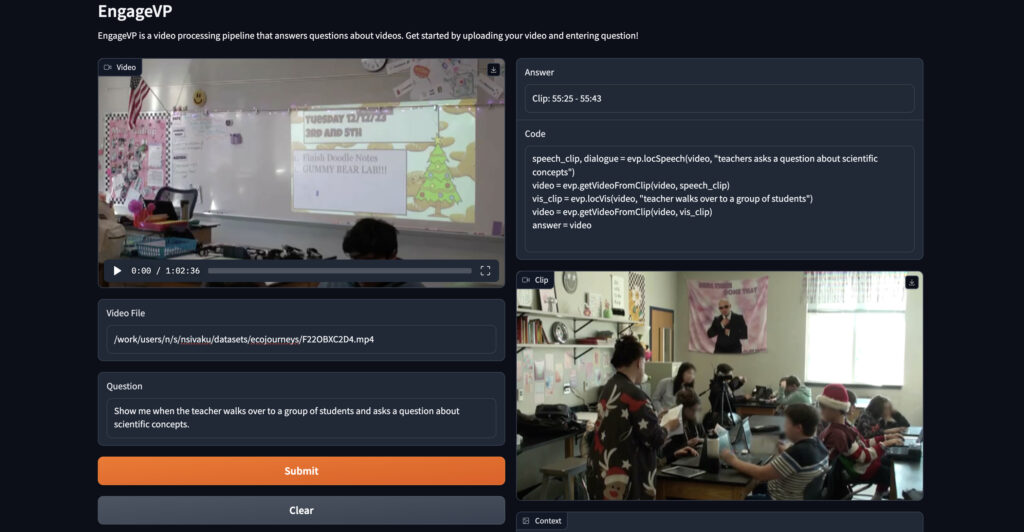
The team’s recent work builds on a model named SeViLA (self-chained image-language modeling for video localization and question answering), a novel framework previously developed by EngageAI that leverages a single image-language model (BLIP-2) to tackle both temporal keyframe localization and question answering on videos. Building upon this foundation, the team has developed a more advanced framework named EngageVP for classroom video analysis by incorporating several expert models (e.g., whisperX, Mistral, CREMA, etc.) together to perform complex tasks such as predicting student joint attention or performing gaze and audio/dialogue engagement analysis. The framework uses “visual programming”, a method of chaining together pre-trained expert models via LLM code generation. That is, the LLM generates code that will run the relevant expert models for a given question. This allows the framework to operate in a zero-shot/few-shot setting, although the LLM still needs a few examples to achieve reasonable performance. EngageVP features several video-language analysis capabilities, including moment localization, question answering, audio/dialogue engagement analysis, and gaze detection.
EngageVP has been tested on several classroom videos capturing collaborative learning with the EcoJourneys narrative-centered learning environment that were annotated by learning scientists from Indiana University. The framework has been tested with a set of question-answer pairs addressing multiple different aspects of student behavior such as speech/conversations (finding where a specific conversation happened or detecting specifics about disagreements/agreements among the students), general student engagement/socioemotional states of the students (retrieving when students are confused/frustrated or gauging overall student contribution in a discussion), and visual events (finding where people are located or when a specific action occurred).
Initial results indicate that the framework is able to tell if students are actively engaged in their work or if they are getting off-topic and not paying attention, successfully analyze student collaboration such as identifying agreements/disagreements among students, and analyze interactions between teachers and students such as by identifying what questions the teacher poses to their students and the students’ responses.
Upcoming Plans: The EngageVP framework will be tested with more classroom videos and more types of engagement analysis (e.g., analyzing if students in a group showed higher or lower-quality engagement during the collaboration or having the framework analyze student actions within the EcoJourneys game). Additionally, while the EngageVP framework already includes many features such as video question answering, speech analysis, moment localization, and gaze tracking, it is easily extensible to include other features. The team is actively adding new features (e.g., emotion detection and speaker identification) based on testing results with classroom videos. If testing indicates that the EngageVP framework cannot handle a certain analysis in a video, then the team will actively try to upgrade and incorporate more features to allow that analysis to be handled.