
Authors: Umesh Timalsina, Eduardo Davalos
Key Ideas
- Engage AI has the goal of coming up with a unified software architecture to collect and process data from educational learning environments at scale.
- Challenges of building a system for collecting and processing data include integrations, synchronization, privacy, scalability, data quality, and ethical concerns.
- SyncFlow can help streamline compatible classroom data by collecting, processing, and storing multimodal data on a large scale.
As research engineers, we’re taking a moment to reflect on our current development of a platform and infrastructure for collecting and analyzing multimodal data for education. The eventual goal of our project is to come up with a unified software architecture to collect and process data from educational learning environments at scale with goals to: (a) automate the process of collecting, streaming, and analyzing multimodal data (audio, video, other sensors) and (b) generate meaningful artifacts—such as audio transcripts, pose, gestures, and gaze—as feedback to learning environments and researchers for tangible research outcomes, as well as enhanced teaching and learning experiences for teachers and students.
Multimodal learning analytics (MMLA) uses data streams of different types to analyze and provide feedback to researchers/educators on overall performance of students performing a learning activity, typically using computers in what are called Computer Based Learning Environments (CBLEs). Depending on the nature of the activity, researchers are often looking for data such as affect detection, log analysis, or audio transcription. Some of these analytics methods are available in real time.
Multimodal data collection in a typical classroom research project usually spans from a few days to months. For each session, students are assigned a particular learning experience, and these learning experiences are usually gamified (some are even games that the students play). For each session, depending on the kinds of analysis needed, researchers usually collect application logs, students’ audio and video, overall classroom video/audio, teacher and researcher interviews, and data from a wide array of sensors like eye trackers, heartbeat sensors, positional data, etc. Well, that’s a lot right? Complicating things, the systems generating this volume of data are isolated from each other, and researchers end up spending more time wrestling with disparate formats and stitching pipelines together than on the actual analysis—delaying insights and eating into limited study budgets. Additionally, for a session—running from a few minutes to an hour or two—a unified timeline is needed to do a segmented analysis, so all the collected data can be analyzed as a whole or in segments.
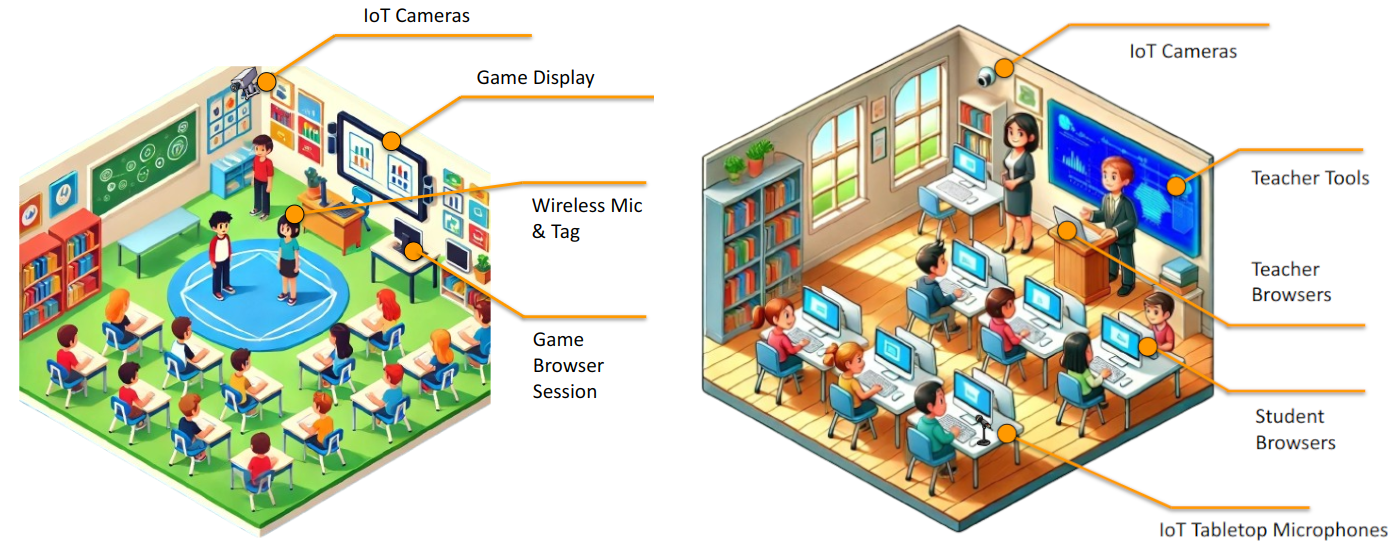
When attempting to build a system for collection and processing data, we encountered several challenges:
- Integration: It is challenging to bring all the stakeholders together
- Synchronization: Different systems generate data at different rates causing disparity in collection frequency and time alignment
- Privacy: How to protect and secure identifiable data
- Scalability: How to ensure that hundreds of participants’ data can be collected effectively
- Data Quality: Ensure the data is high quality (for any meaningful automated analysis)
- Ethical Concerns: Ensure that the system we build doesn’t compromise student privacy, introduce algorithmic biases, or collect sensitive information without informed consent
Our goal throughout the endeavor was to develop and build integration channels for this system, which we’re aptly calling the Multimodal Learning Analytics Pipeline (MMLA Pipeline).
This is when we brewed the idea for “SyncFlow: Harmonize Your Data Streams.” We set out to build an orchestration dashboard that various learning environments could use and reuse to preview and record classroom data, as long as they are integrated to our system. The data streaming in SyncFlow would run on LiveKit, an open-source video conferencing platform. The full system was designed to handle the entire process of collecting, processing, and storing multimodal data on a large scale. After building the first version, we tested SyncFlow by collecting data for an I-ACT study at a middle school in the Midwest.

After the first successful test, we refined SyncFlow architecture to support multiple studies at the same time and connected it to several EngageAI learning environments still in development. While SyncFlow can run in the cloud, it can also be set up locally for situations where internet access is limited or when research procedures, such as IRB restrictions, do not allow for cloud-based solutions.
The road ahead is promising. The MMLA Pipeline helps not only with collecting data but also with analyzing it and giving useful feedback. We invite researchers, educators, and developers to collaborate with us on this project. By joining our open-source effort, you can help improve real-time tools for data collection, analysis, and feedback that support better learning. Together, we can solve integration challenges and make a real impact on education.
If you have any questions or suggestions, please reach out to Umesh Timalsina or Eduardo Davalos.
A more detailed and technical version of this blog post can be found here.